
Elena Canorea
Communications Lead
Intro
El campo de la visión artificial y la IA ha experimentado un increíble crecimiento durante los últimos años.
La capacidad de las redes neuronales para reconocer patrones complejos en los datos las convierte en una herramienta importante para la IA. Te explicamos a fondo su funcionamiento y los casos de uso más importantes.
Las Convolutional Neural Network (CNN) o redes neuronales convolucionales son un subconjunto del Machine Learning y son el corazón de los algoritmos de Deep Learning. Están compuestas por capas de nodos que contienen una capa de entrada, una o más capas ocultas y una capa de salida.
Cada nodo se conectar a otro y tiene un peso y umbral asociados. Si la salida de cualquier nodo individual supera el valor de umbral especificado, ese nodo se activa y envía datos a la siguiente capa de la red. De lo contrario, no se transmiten datos a la siguiente capa de la red.
Son particularmente eficaces para procesar y analizar datos visuales, y se utilizan distintos tipos de redes neuronales para distintos tipos de datos y casos de uso. Por ejemplo, las redes neuronales recurrentes suelen utilizarse para procesar el lenguaje natural y el reconocimiento de voz, mientras que las CNN se emplean más para tareas de clasificación y visión artificial.
Antes de empezar, hay que dejar claros algunos conceptos básicos sobre redes neuronales:
Las redes neuronales convolucionales utilizan una serie de capas, cada una de las cuales detecta distintas características de una imagen de entrada. Según la complejidad de su finalidad, una CNN puede contener hasta miles de capas, cada una de las cuales se basan en los resultados de las anteriores para reconocer patrones detallados.
El proceso comienza deslizando un filtro diseñado para detectar ciertas características sobre la imagen de entrada, conocido como operación de convolución. El resultado de este proceso es un mapa de características que resalta la presencia de las características detectadas de la imagen.
Los filtros iniciales suelen detectar características básicas, como líneas o texturas simples. Los filtros de las capas posteriores son más complejos y combinan las características básicas identificadas anteriormente para reconocer patrones más complejos.
Entre estas capas, la red toma medidas para reducir las dimensiones espaciales de los mapas de características a fin de mejorar la eficiencia y la precisión. En las capas finales, el modelo toma una decisión final en función del resultado de las capas anteriores.
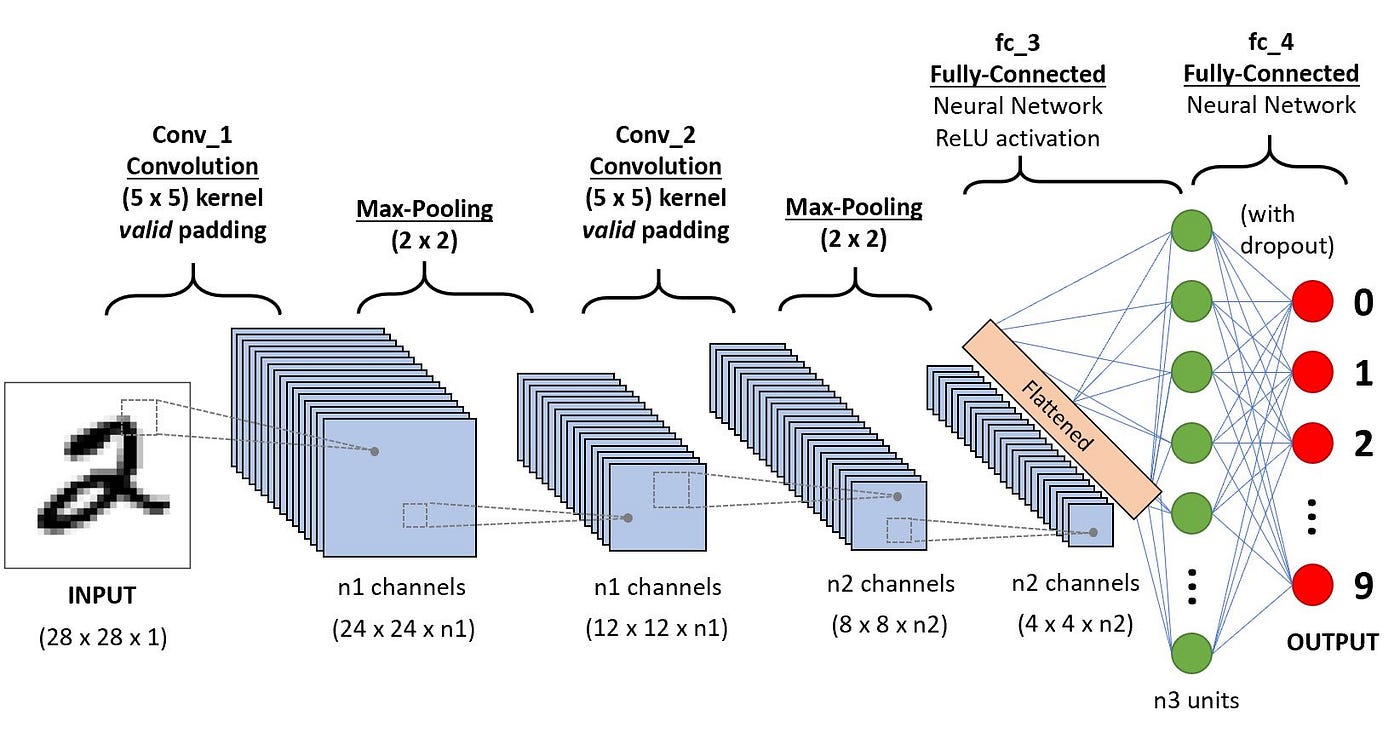
Fuente: Towards Data Science
Como hemos dicho más arriba, el funcionamiento de las CNN puede parece simple a primera vista: el usuario proporciona una imagen de entrada en forma de matriz de píxeles, la cual tiene 3 dimensiones:
A diferencia de un modelo estándar de perceptrón multicapa (MLP), que contiene solo una parte de clasificación, la arquitectura de la red convolucional tiene varias capas
Este es el componente fundamental de una CNN y donde se realizan la mayoría de los cálculos. Esta capa utiliza un filtro o núcleo para moverse a través del campo receptivo de una imagen de entrada y detectar la presencia de características específicas.
El proceso comienza deslizando el núcleo sobre el ancho y la altura de la imagen, para luego recorrer toda la imagen en varias iteraciones. En cada posición se calcula un producto escalar entre los pesos del núcleo y los valores de los píxeles de la imagen bajo el núcleo. Esto transforma la imagen de entrada en un conjunto de mapas de características, cada una de las cuales representa la presencia e intensidad de una característica determinada en varios puntos de la imagen.
Supongamos que la entrada es una imagen en color, que está formada por una matriz de píxeles en 3D. Así, la entrada tendrá tres dimensiones (alto, ancho y profundidad), además de un detector de características, que se moverá por los campos receptivos de la imagen para comprobar si la característica está presente (convolución).
Este detector o filtro es una matriz bidimensional de pesos que representa parte de la imagen. Aunque puede variar de tamaño, suele ser una matriz de 3×3, lo que también determina el tamaño del campo receptivo. Este filtro se aplica a un área de la imagen y se calcula un producto escalar entre los píxeles de entrada y el filtro. Este producto escalar se introduce en una matriz de salida. El resultado final de la serie de productor escalares de la entrada y el filtro se conoce como mapa de características, mapa de activación o característica convolucionada.
Algunos parámetros se ajustan durante el entrenamiento a través del proceso de retropropagación y descenso de gradiente. Pero hay tres parámetros que afectan el tamaño del volumen de la salida que deben configurarse antes de que comience el entrenamiento de la red neuronal:
Después de cada operación, una CNN aplica una transformación de unidad lineal rectificada al mapa de características, introduciendo no linealidad en el modelo.
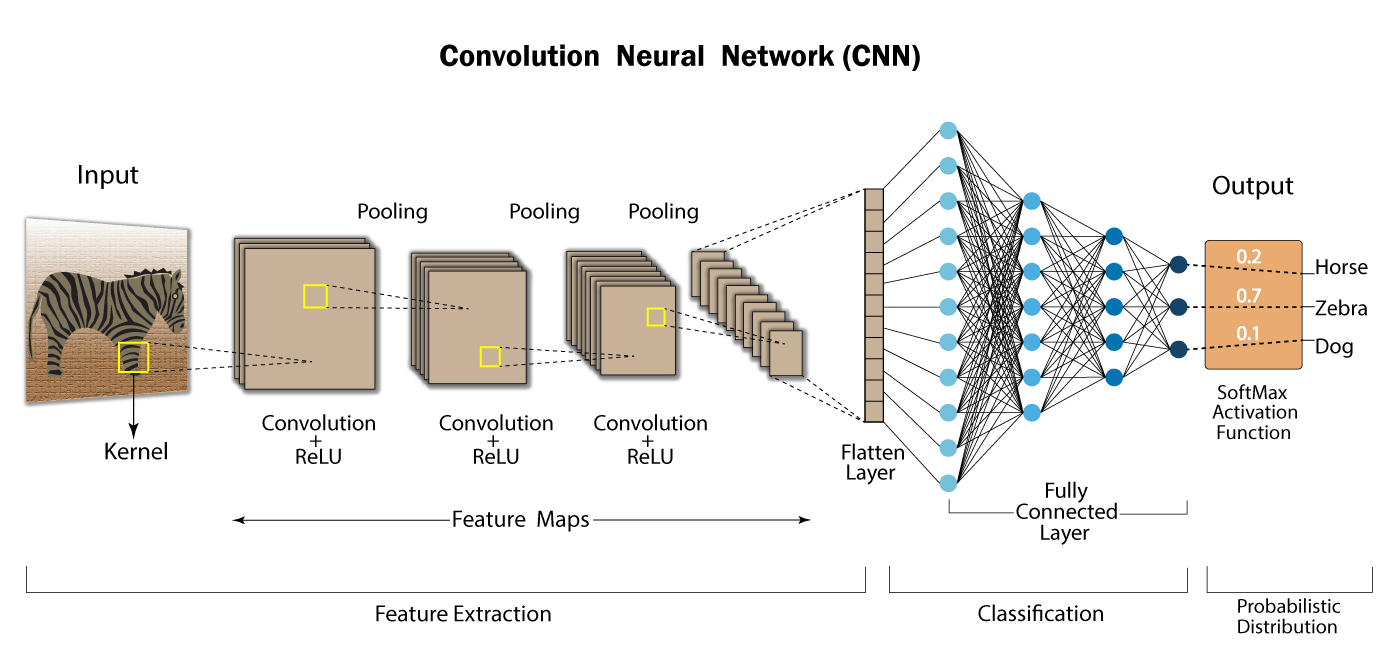
Fuente: Developers Break
Cuando una capa de convolución sigue a la capa inicial, la estructura de la CNN puede volverse jerárquica, ya que las capas posteriores pueden ver los píxeles dentro de los campos receptivos de las capas anteriores.
Cada parte individual de la imagen conforman un patrón de nivel inferior en la red neuronal, y la combinación de sus partes representa un patrón de nivel superior, creando una jerarquía de características dentro de la CNN. Finalmente, la capa convolucional convierte la imagen en valores numéricos, lo que permite que la red neuronal interprete y extraiga patrones relevantes.
También conocidas como reducción de muestreo, realizan una reducción de dimensionalidad, lo que reduce la cantidad de parámetros en la entrada.
De manera similar a la primera capa, la operación de agrupamiento barre con un filtro toda la entrada, pero la diferencia es que este filtro no tiene pesos. En cambio, el núcleo aplica una función de agregación a los valores dentro del campo receptivo, llenando la matriz de salida. Hay dos tipos:
La desventaja de esta capa es que se puede perder mucha información, pero también ayuda a reducir la complejidad, mejorar la eficiencia y limitar el riesgo de sobreajuste.
Los valores de los píxeles de la imagen de entrada no están conectados directamente a la capa de saluda en las capas parcialmente conectadas. Ahí es donde entra la capa completamente conectada, donde cada nodo de la capa de salida se conecta directamente a un nodo de la capa anterior.
Esta capa realiza la tarea de clasificación en función de las características extraídas a través de las capas anteriores y sus diferentes filtros
Antes de que existieran las CNN, los objetos se identificaban mediante métodos de extracción de características que consumían mucho tiempo y que debían llevarse a cabo manualmente. Con estas redes convolucionales se obtiene un enfoque más escalable para la clasificación de imágenes y la detección de objetos.
Al emplear principios de álgebra lineal, las CNN pueden reconocer patrones en una imagen. Por ello, sus aplicaciones más extendidas son:
Las redes neuronales convolucionales (CNN) y las redes generativas antagónicas (GAN) son dos tecnologías fundamentales que han desempeñado papeles fundamentales en el avance de la visión artificial.
Como resumen de lo ya hablado a lo largo del artículo, las CNN se inspiran en la estructura y el funcionamiento del sistema visual humano y constan de varias capas, incluidas capas convolucionales, capas de agrupación y capas completamente conectadas.
Por su parte, las Generative Adversarial Network (GAN) constan de dos redes neuronales, un generador y un discriminador, que se entrenan simultáneamente a través de un proceso competitivo. El generador intenta crear datos falsos que no se pueden distinguir de los datos reales, mientras que el discriminador intenta diferenciar entre datos reales y falsos. Las GAN son más conocidas por sus capacidades generativas y su potencial para crear imágenes realistas, pero también tienen aplicaciones en el procesamiento de imágenes para la visión artificial.
Si comparamos una con otra, las principales diferencias que encontramos son las siguientes:
Las CNN están diseñadas para la extracción de características gracias al uso de capas convolucionales para capturar estas características jerárquicas de los datos de entrada. Esto es crucial para tareas como el reconocimiento, la segmentación y la detección de objetos. Además, pueden aprender características discriminativas directamente de los datos.
Por su parte, las GAN no están diseñadas intrínsecamente para la extracción de características. Aunque su discriminador aprende a diferenciar características, no es su propósito principal, pues se centran en la generación y manipulación de datos.
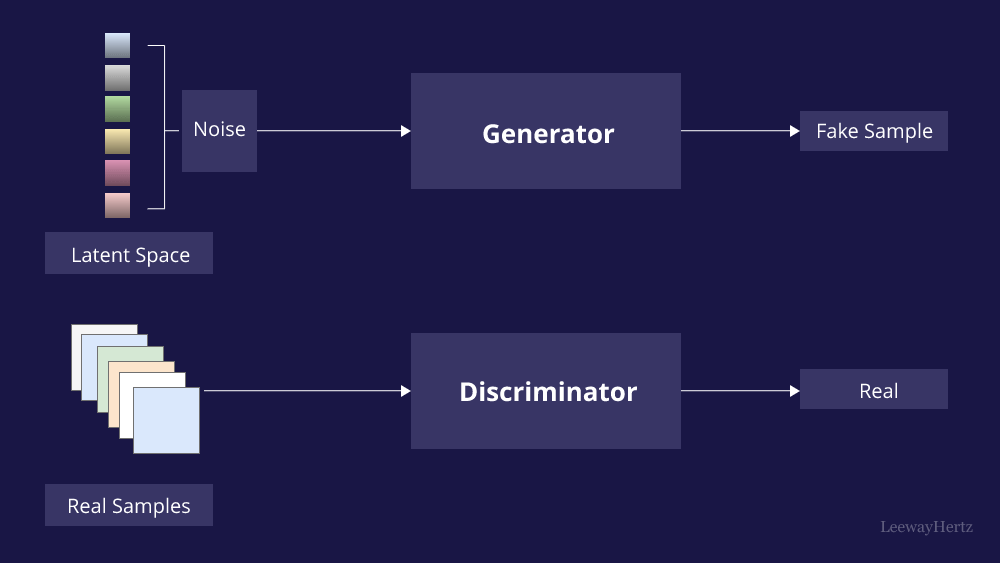
Fuente: LeewayHertz
Como ya hemos comentado antes, la función principal de las CNN es procesar datos existentes para tareas de clasificación, detección o segmentación, no suelen utilizarse para la generación de datos. Sin embargo, hay algunas variantes, como los autocodificadores variacionales (VAE), que pueden adaptarse para la generación de datos.
Al contrario, las GAN destacan en esta tarea, pues pueden crear imágenes sumamente realistas, lo que las convierte en la mejor opción para casos de uso como síntesis de imágenes, superresolución y transferencia de estilo.
En este caso, las CNN son muy adecuadas para el aprendizaje por transferencia, pues hay modelo preentrenados disponibles y fácil de ajustar para tareas específicas, lo que es muy beneficioso cuando se trabaja con datos limitados.
Por su parte, aunque los GAN se utilizan con menos frecuencia en este escenario, algunos modelos están entrenados previamente.
Las CNN son modelos discriminativos, ya que se centran en distinguir y clasificar datos.
Al contrario, las GAN son modelos generativos, diseñadas para crear nuevos datos que se pueden distinguir de los datos reales.
Las CNN procesan imágenes existentes, no las producen, por lo que su rendimiento depende de la calidad y cantidad de los datos utilizados para el entrenamiento. Aunque son capaces de lograr una alta precisión en tareas de reconocimiento, no generar imágenes realistas de manera inherente.
Las GAN tienen la capacidad de producir imágenes que pueden «engañar» a los humanos debido a su realismo, por lo que han establecido puntos de referencia en la generación y calidad de imágenes.
Por un lado, encontramos las CNN, que requieren de un gran esfuerzo computacional durante el entrenamiento, especialmente cuando se trabaja con arquitecturas profundas y grandes conjuntos de datos. Aunque también son relativamente rápidas a la hora de realizar predicciones una vez entrenadas.
Las GAN también requieren de un uso intensivo de recursos computaciones y de entrenamiento. Al tener estas demandas, las aplicaciones en tiempo real pueden ser un desafío.
En este tema encontramos similitudes, pues ambas se enfrentan a desafíos éticos y de seguridad que aún hay que resolver. Por ejemplo, las CNN han suscitado preocupaciones éticas relacionados con la privacidad, los prejuicios y la vigilancia, especialmente con lo relativo al reconocimiento facial.
Las GAN no se quedan atrás en estos retos, pues su uso para crear deepfakes hace que se planteen problemas importantes éticos y de seguridad, pues se puede utilizar la tecnología para desinformar, suplantar la identidad u otros fines maliciosos.
Por tanto, tanto las CNN como las GAN tienen sus propias ventas y aplicaciones en el campo de la IA, especialmente en la visión artificial. La elección entre una u otra depende de los requisitos específicos de la tarea a realizar. Las CNN son la opción ideal para tareas que implican reconocer y analizar datos existentes, mientras que las GAN destacan en tareas que exigen generación de datos, síntesis de imágenes y expresión creativa.
Sin embargo, estas tecnologías no son mutuamente excluyentes, pues, en algunas aplicaciones, se pueden complementar entre sí. A medida que la visión artificial siga evolucionando, tanto una como otra desempeñarán un papel fundamental en la configuración del futuro de la percepción y la comprensión visual.
Las CNN han revolucionado el campo de la IA y ofrece numerosos beneficios en diversos sectores. De hecho, otros avances, como las mejoras de hardware, los nuevos métodos de recopilación de datos y las arquitecturas avanzadas, como las redes de cápsulas, pueden optimizar aún más las CNN e integrarlas en más tecnologías, lo que se traduce en una ampliación de casos de uso.
Si quieres llevar tu negocio al siguiente con las soluciones de inteligencia artificial que mejor se adapten a tu caso, los expertos de Plain Concepts pueden ayudarte. Diseñamos tu estrategia, proteger tu entorno, elegir las mejores soluciones, cerrar las brechas de tecnología y datos, y a establecer una supervisión rigurosa que consiga una IA responsable. Así podrás lograr un aumento rápido de la productividad y construir las bases para nuevos modelos comerciales basados en la hiperpersonalización o el acceso continuo a los datos e información relevante.
Contamos con un equipo de expertos que lleva aplicando exitosamente esta tecnología en numerosos proyectos, asegurando la seguridad de los clientes. Llevamos más de 10 años llevando la IA a nuestros clientes y ahora te proponemos un Framework de adopción de IA:
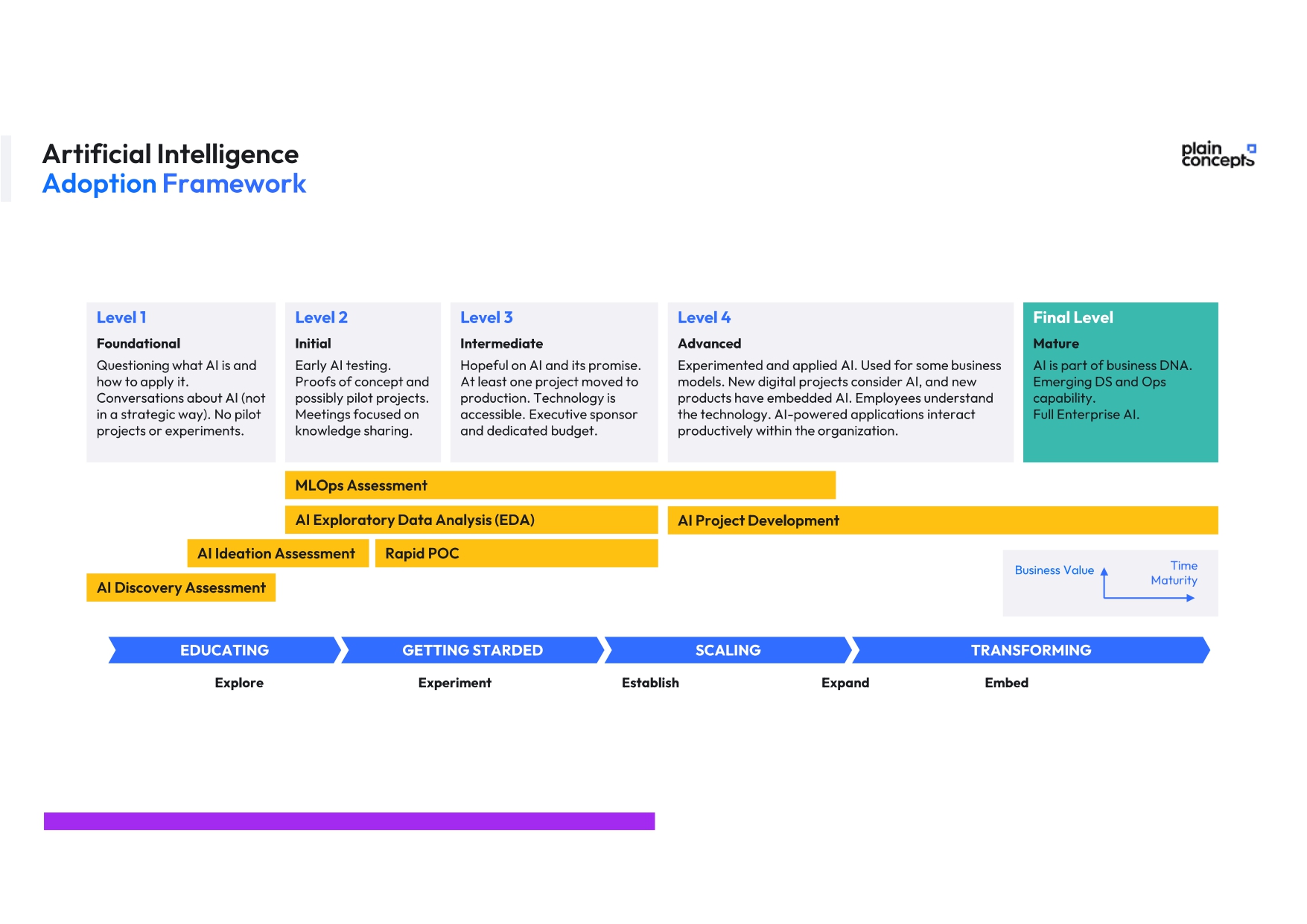
¡Comienza tu viaje a la innovación desde hoy mismo!
Elena Canorea
Communications Lead
