
Elena Canorea
Communications Lead
Intro
The field of computer vision and AI has experienced incredible growth over the past few years.
The ability of neural networks to recognize complex patterns in data makes them an important tool for AI. We explain in depth how they work and the most important use cases.
Convolutional Neural Networks (CNN) are a subset of Machine Learning and are at the heart of Deep Learning algorithms. They are composed of layers of nodes containing an input layer, one or more hidden layers, and an output layer.
Each node connects to another and has an associated weight and threshold. If the output of any individual node exceeds the specified threshold value, that node becomes active and sends data to the next network layer. Otherwise, no data is transmitted to the next network layer.
They are particularly effective for processing and analyzing visual data, and different types of neural networks are used for different types of data and use cases. For example, recurrent neural networks are typically used to process natural language and speech recognition, while CNNs are used more for classification and computer vision tasks.
Before starting, it is necessary to clarify some basic concepts about neural networks:
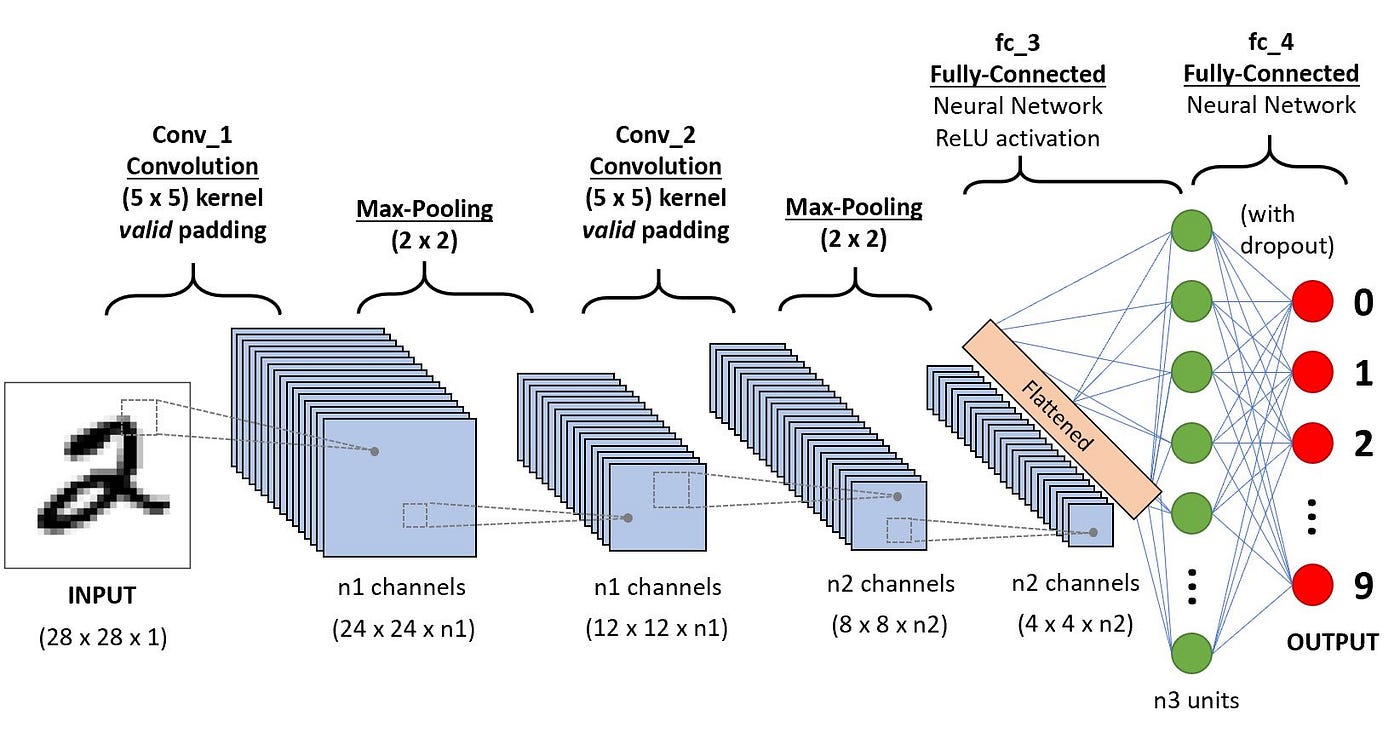
Convolutional neural networks use a series of layers, each detecting different features of an input image. Depending on the complexity of its purpose, a CNN can contain up to thousands of layers, each of which builds on the results of the previous layers to recognize detailed patterns.
The process begins by sliding a filter designed to detect certain features over the input image, known as a convolution operation. The result of this process is a feature map that highlights the presence of the detected image features.
Initial filters typically detect basic features, such as lines or simple textures. Later layer filters are more complex and combine the basic features identified earlier to recognize more complex patterns.
Between these layers, the network takes steps to reduce the spatial dimensions of the feature maps to improve efficiency and accuracy. In the final layers, the model makes a final decision based on the output of the previous layers.
Source: Towards Data Science
As mentioned above, the operation of CNNs may seem simple at first glance: the user provides an input image in the form of a pixel array, which has 3 dimensions:
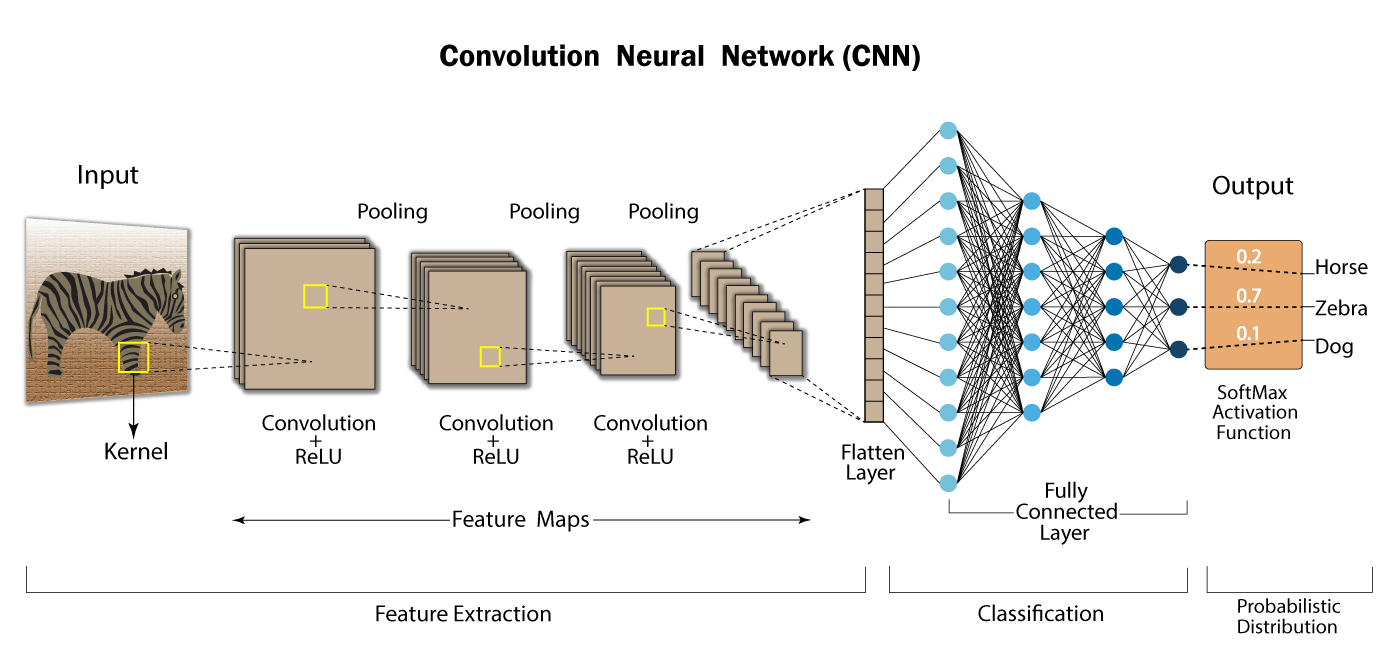
Unlike a standard multilayer perceptron (MLP) model, which contains only a single classification part, the convolutional network architecture has several layers:
This is the fundamental component of a CNN and where most of the calculations are performed. This layer uses a filter or kernel to move through the receptive field of an input image and detect the presence of specific features.
The process begins by sliding the kernel over the width and height of the image, and then traversing the entire image in several iterations. At each position, a scalar product is computed between the kernel weights and the image pixel values under the kernel. This transforms the input image into a set of feature maps, each of which represents the presence and intensity of a given feature at various points in the image.
Suppose the input is a color image, which is made up of a 3D array of pixels. Thus, the input will have three dimensions (height, width, and depth), plus a feature detector, which will move through the receptive fields of the image to check if the feature is present (convolution).
This detector or filter is a two-dimensional array of weights representing part of the image. Although it can vary in size, it is usually a 3×3 matrix, which also determines the size of the receptive field. This filter is applied to an area of the image and a scalar product is calculated between the input pixels and the filter. This scalar product is fed into an output matrix. The final result of the series of scalar products of the input and the filter is known as a feature map, activation map, or convolved feature.
Some parameters are adjusted during training through the process of backpropagation and gradient descent. However, there are three parameters that affect the size of the output volume that must be set before neural network training begins:
After each operation, a CNN applies a rectified linear unit transformation to the feature map, introducing nonlinearity into the model.
Source: Developers Break
When a convolution layer follows the initial layer, the structure of the CNN can become hierarchical, as later layers can see pixels within the receptive fields of earlier layers.
Each individual part of the image forms a lower-level pattern in the neural network, and the combination of its parts represents a higher-level pattern, creating a hierarchy of features within the CNN. Finally, the convolutional layer converts the image into numerical values, allowing the neural network to interpret and extract relevant patterns.
Also known as downsampling, they perform dimensionality reduction, which reduces the number of parameters in the input.
Similar to the first layer, the clustering operation sweeps the entire input with a filter, but the difference is that this filter has no weights. Instead, the kernel applies an aggregation function to the values within the receptive field, filling the output matrix. There are two types:
The disadvantage of this layer is that a lot of information can be lost, but it also helps to reduce complexity, improve efficiency, and limit the risk of overfitting.
The pixel values of the input image are not directly connected to the greeting layer in the partially connected layers. That’s where the fully connected layer comes in, where each node in the output layer is directly connected to a node in the previous layer.
This layer performs the classification task based on the features extracted through the previous layers and their different filters.
Before CNNs existed, objects were identified using time-consuming feature extraction methods that had to be performed manually. With these convolutional networks, a more scalable approach to image classification and object detection is achieved.
By employing linear algebra principles, CNNs can recognize patterns in an image. Therefore, their most widespread applications are:
Convolutional neural networks (CNNs) and generative antagonistic networks (GANs) are two fundamental technologies that have played key roles in the advancement of computer vision.
To summarize what has already been discussed throughout the article, CNNs are inspired by the structure and functioning of the human visual system and consist of several layers, including convolutional layers, grouping layers, and fully connected layers.
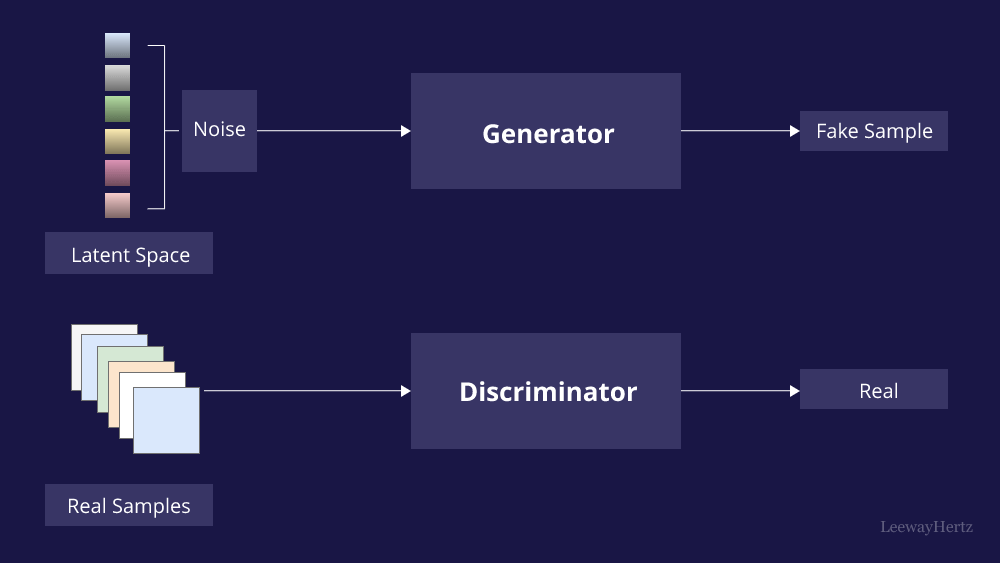
Generative Adversarial Networks (GANs), on the other hand, consist of two neural networks, a generator and a discriminator, which are trained simultaneously through a competitive process. The generator attempts to create false data that cannot be distinguished from real data, while the discriminator attempts to differentiate between real and false data. GANs are best known for their generative capabilities and their potential to create realistic images, but they also have applications in image processing for computer vision.
If we compare one with the other, the main differences are as follows:
CNNs are designed for feature extraction by using convolutional layers to capture these hierarchical features from the input data. This is crucial for tasks such as recognition, segmentation, and object detection. In addition, they can learn discriminative features directly from the data.
GANs, on the other hand, are not intrinsically designed for feature extraction. Although their discriminator learns to differentiate features, it is not their primary purpose, as they focus on data generation and manipulation.
Source: LeewayHertz
As discussed earlier, the primary function of CNNs is to process existing data for classification, detection, or segmentation tasks, they are not typically used for data generation. However, there are some variants, such as variational autoencoders (VAE), that can be adapted for data generation.
On the contrary, GANs excel in this task, as they can create highly realistic images, making them the best choice for use cases such as image synthesis, super-resolution, and style transfer.
In this case, CNNs are well suited for transfer learning, as pre-trained models are available and easy to tune for specific tasks, which is very beneficial when working with limited data.
In turn, although GANs are less frequently used in this scenario, some models are pre-trained.
CNNs are discriminative models, as they focus on distinguishing and classifying data.
On the contrary, GANs are generative models, designed to create new data that can be distinguished from real data.
CNNs process existing images, not produce them, so their performance depends on the quality and quantity of data used for training. Although they are capable of achieving high accuracy in recognition tasks, they do not inherently generate realistic images.
GANs have the ability to produce images that can “fool” humans due to their realism, so they have set benchmarks in image generation and quality.
On the one hand, we find CNNs, which require a great computational effort during training, especially when working with deep architectures and large datasets. However, they are also relatively fast when making predictions once trained.
GANs are also computationally and training resource intensive. With these demands, real-time applications can be challenging.
Here we find similarities, as both face ethical and security challenges that have yet to be resolved. For example, CNNs have raised ethical concerns related to privacy, bias, and surveillance, especially with regard to facial recognition.
GANs are not far behind in these challenges, as their use to create deepfakes raises significant ethical and security issues, as the technology can be used for misinformation, impersonation, or other malicious purposes.
Therefore, both CNNs and GANs have their own sales and applications in the field of AI, especially in computer vision. The choice between one or the other depends on the specific requirements of the task at hand. CNNs are the ideal choice for tasks that involve recognizing and analyzing existing data, while GANs excel in tasks that require data generation, image synthesis, and creative expression.
However, these technologies are not mutually exclusive; in some applications, they can complement each other. As machine vision continues to evolve, both will play a key role in shaping the future of visual perception and understanding.
CNNs have revolutionized the field of AI and offer numerous benefits in a variety of industries. In fact, other advances such as hardware enhancements, new data collection methods, and advanced architectures such as capsule networks can further optimize CNNs and integrate them into more technologies, resulting in expanded use cases.
If you want to take your business to the next level with the artificial intelligence solutions that best fit your case, the experts at Plain Concepts can help. We’ll design your strategy, protect your environment, choose the best solutions, close technology and data gaps, and establish rigorous oversight to achieve responsible AI. So you can achieve rapid productivity gains and build the foundation for new business models based on hyper-personalization or continuous access to relevant data and information.
We have a team of experts who have been successfully applying this technology in numerous projects, ensuring the security of our clients. We have been bringing AI to our clients for more than 10 years and now we propose an AI Adoption Framework:
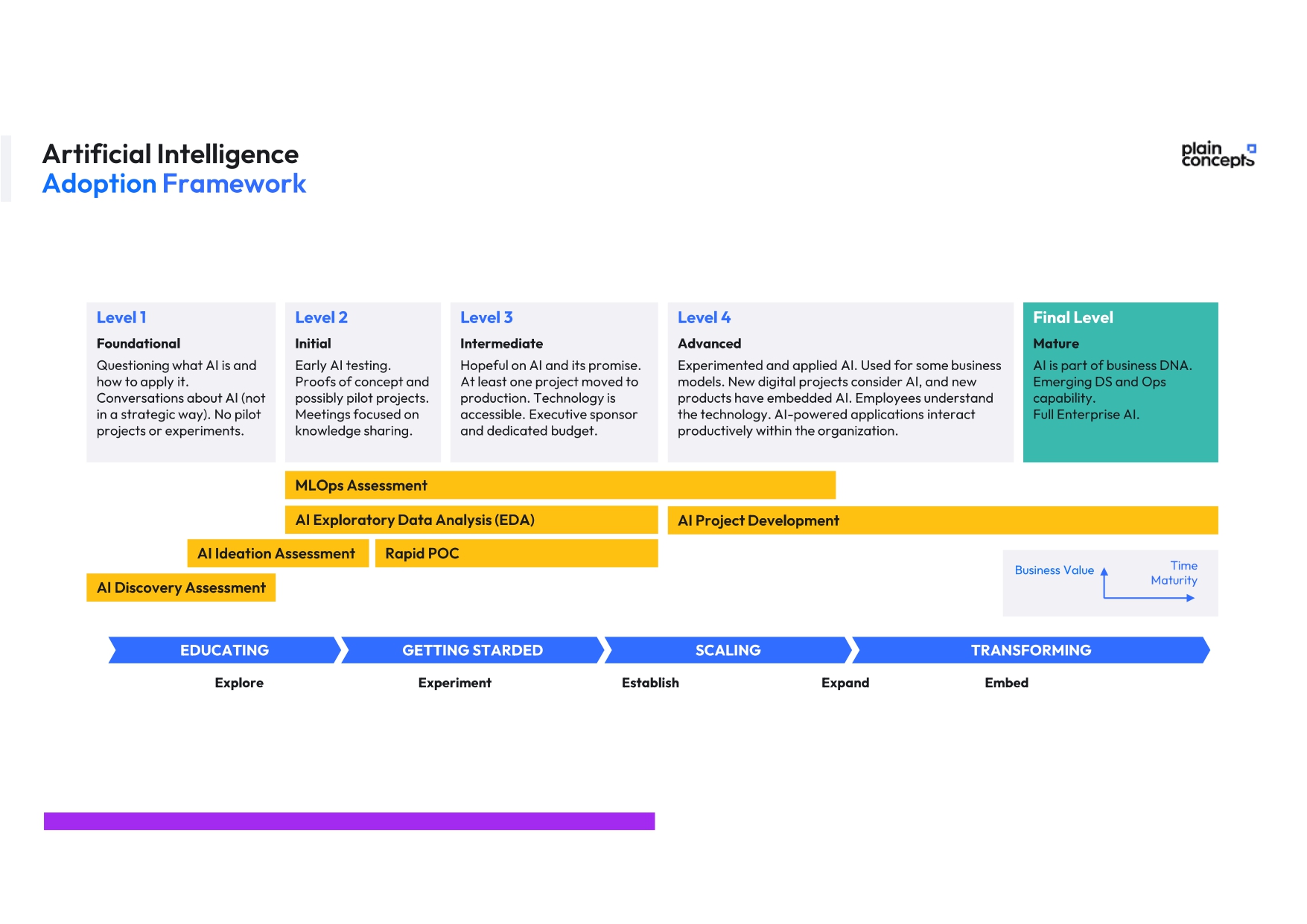
Start your journey to innovation today!
Elena Canorea
Communications Lead
